Sunday, November 22, 2009
Running the last launch configuration in Eclipse
Just in case I forget one day: if you want to get rid of that annoying guessgame Eclipse 3.5 does when hitting F11 you have to change the "Launch Operations" option in Window->Preferences->Run/Debug->Launching to "Always launch the previously launched application". Afterwards the F11 will do what I always want it do. Admittably the Ctrl+Alt+X shortcuts are unwieldy, but they are good enough to launch something specific in the rare cases I want that.
Monday, July 27, 2009
Functional testing of WARs with Maven
I just finished setting up a configuration where a separate Maven project is used to run some JWebUnit tests on a web application. The focus is on regularly checking the application functionality, so we don't care about running on the production stack (yet), we rather want an easy to run and quick test suite.
We assume that the application we want to run defaults to some standalone setup, e.g. by using something like an in-memory instance of hsqldb as persistence solution. It also has to be available via Maven, in the simple case by running a "mvn install" locally, the nicer solution involves running your own repository (e.g. using Artifactory).
Here is a sample POM for such a project he rest of the story is in the inline documentation:
Note that in this case we depend on a SNAPSHOT release of our own app. This means that you can nicely run this test in your continuous integration server, triggered by the successful build of your main application (as well as any change in the tests itself). If you use my favorite CI server Hudson, then you can even tell it to aggregate the test results onto the main project.
Having a POM like this you can launch straight into the JWebUnit Quickstart. A basic setup needs only the POM and one test case in
You can also switch the Servlet engine or deploy into a running one. The Cargo documentation is pretty decent, so I recommend looking at that. They certainly know more Servlet engines than I do.
If you use profiles to tweak Cargo in the right way, you should be able to run the same test suite against a proper test system using the same stack as your production environment. I haven't gone there yet, but I intend to. The setup used here is really intended for regular tests after each commit. By triggering them automatically on the build server the delay doesn't burden the developers, but they are still fast enough to give you confidence in what you are doing.
We assume that the application we want to run defaults to some standalone setup, e.g. by using something like an in-memory instance of hsqldb as persistence solution. It also has to be available via Maven, in the simple case by running a "mvn install" locally, the nicer solution involves running your own repository (e.g. using Artifactory).
Here is a sample POM for such a project he rest of the story is in the inline documentation:
<!--
=== POM for testing a war file coming out of a separate build. ===
Basic idea:
- run Surefire plugin for tests, but in the integration-test phase
- use Cargo to start an embedded Servlet engine before the integration-tests, shut it down afterwards
- use tests written with JWebUnit with the HtmlUnit backend to do the actual testing work
This configuration can be run with "mvn integration-test".
-->
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>my.org</groupId>
<artifactId>myApp-test</artifactId>
<name>MyApp Test Suite</name>
<version>1.0.0-SNAPSHOT</version>
<description>A set of functional tests for my web application</description>
<build>
<plugins>
<plugin>
<!-- The Cargo plugin manages the Servlet engine -->
<groupId>org.codehaus.cargo</groupId>
<artifactId>cargo-maven2-plugin</artifactId>
<executions>
<!-- start engine before tests -->
<execution>
<id>start-container</id>
<phase>pre-integration-test</phase>
<goals>
<goal>start</goal>
</goals>
</execution>
<!-- stop engine after tests -->
<execution>
<id>stop-container</id>
<phase>post-integration-test</phase>
<goals>
<goal>stop</goal>
</goals>
</execution>
</executions>
<configuration>
<!-- we use a Jetty 6 -->
<container>
<containerId>jetty6x</containerId>
<type>embedded</type>
</container>
<!-- don't let Jetty ask for the Ctrl-C to stop -->
<wait>false</wait>
<!-- the actual configuration for the webapp -->
<configuration>
<!-- pick some port likely to be free, it has be matched in the test definitions -->
<properties>
<cargo.servlet.port>9635</cargo.servlet.port>
</properties>
<!-- what to deploy and how (grabbed from dependencies below) -->
<deployables>
<deployable>
<groupId>my.org</groupId>
<artifactId>my-webapp</artifactId>
<type>war</type>
<properties>
<context>/</context>
</properties>
</deployable>
</deployables>
</configuration>
</configuration>
</plugin>
<plugin>
<!-- configure the Surefire plugin to run integration tests instead of the
running in the normal test phase of the lifecycle -->
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<configuration>
<skip>true</skip>
</configuration>
<executions>
<execution>
<phase>integration-test</phase>
<goals>
<goal>test</goal>
</goals>
<configuration>
<skip>false</skip>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
<dependencies>
<!-- we use the HTML unit variant of JWebUnit for testing -->
<dependency>
<groupId>net.sourceforge.jwebunit</groupId>
<artifactId>jwebunit-htmlunit-plugin</artifactId>
<version>2.2</version>
<scope>test</scope>
<exclusions>
<exclusion>
<groupId>javax.servlet</groupId>
<artifactId>servlet-api</artifactId>
</exclusion>
</exclusions>
</dependency>
<!-- we depend on our own app, so the deployment setup above can find it -->
<dependency>
<groupId>my.org</groupId>
<artifactId>my-webapp</artifactId>
<version>1.0-SNAPSHOT</version>
<type>war</type>
</dependency>
</dependencies>
</project>
Note that in this case we depend on a SNAPSHOT release of our own app. This means that you can nicely run this test in your continuous integration server, triggered by the successful build of your main application (as well as any change in the tests itself). If you use my favorite CI server Hudson, then you can even tell it to aggregate the test results onto the main project.
Having a POM like this you can launch straight into the JWebUnit Quickstart. A basic setup needs only the POM and one test case in
src/test/java. Of course you can use a different testing framework if you want to.You can also switch the Servlet engine or deploy into a running one. The Cargo documentation is pretty decent, so I recommend looking at that. They certainly know more Servlet engines than I do.
If you use profiles to tweak Cargo in the right way, you should be able to run the same test suite against a proper test system using the same stack as your production environment. I haven't gone there yet, but I intend to. The setup used here is really intended for regular tests after each commit. By triggering them automatically on the build server the delay doesn't burden the developers, but they are still fast enough to give you confidence in what you are doing.
Tuesday, May 12, 2009
Inserting new lines with vim regular expressions
If you want to insert new lines with sed-style regular expressions in vim, the usual '\n' doesn't work. The trick is to produce a '^M' by hitting Ctrl-V,Ctrl-M. For example:
will replace the space after the word "word" with a line break across the whole file.
:%s/word /word^M/g
will replace the space after the word "word" with a line break across the whole file.
Thursday, April 9, 2009
Git-SVN for lazy people
Here's what I think is a minimal set of git-svn commands that are sufficient to work offline with a Subversion repository:
Get your copy with
The
Commit changes with
in the top folder. The
This grabs all upstream changes and merges them into your working copy:
To publish the changes you committed locally do:
The "d" in "dcommit" is deliberate. The command pushes all changes you have committed locally back into the original Subversion repository. Your working copy needs to be clean and up-to-date for this to work.
Obviously there is much more you can do, particularly since the local copy is in many ways just a normal git repository. But we wouldn't be lazy if we read about anything more than we need, would we?
Cloning a copy of the repository
Get your copy with
git svn clone http://my.svn.repository/path -s
The
-s indicates a standard trunk/tags/branches layout, otherwise you need to provide --trunk, --tags and --branches to provide your layout.Committing changes
Commit changes with
git commit -a -v
in the top folder. The
-a implicitly adds all files, the -v puts a diff into your commit message editor. Note that there is no "svn" in this command, we are using standard git here.Fetching upstream changes
This grabs all upstream changes and merges them into your working copy:
git svn fetch && git svn rebase
Pushing your changes
To publish the changes you committed locally do:
git svn dcommit
The "d" in "dcommit" is deliberate. The command pushes all changes you have committed locally back into the original Subversion repository. Your working copy needs to be clean and up-to-date for this to work.
Obviously there is much more you can do, particularly since the local copy is in many ways just a normal git repository. But we wouldn't be lazy if we read about anything more than we need, would we?
Thursday, March 12, 2009
Letting Maven use local libraries
Sometimes it is useful to have Maven use some JARs that are checked in with the project, e.g. since you don't trust anything else or you just can't find a library in an existing repository and don't want to run your own.
It actually turns out to be pretty easy. Add something like this to your pom.xml:
Afterwards Maven will try to find a repository in the "lib" folder in your project. Let's assume you want this dependency in the local repository (hopefully something with better chosen IDs, but I decided to keep an existing pattern here):
What you need for this is a folder structure representing those three bits of information: groupId, artifactId and version (in that order), i.e.
To get the SHA1 sums you can do this (assuming you run bash and have the sha1sum tool available):
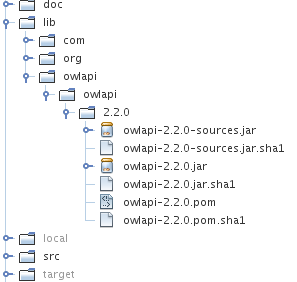
If you are nice and add the sources (has to be a JAR with "-sources" in the name), then the result looks something like this:
The POM itself just contains the basic description (and possible dependencies):
That's all there is -- next time you run Maven it should "download" the files from that location. Considering that the POM also provides a uniform way of storing licence, source and version information it is actually a quite useful approach for storing dependencies inside your project's space.
It actually turns out to be pretty easy. Add something like this to your pom.xml:
<repository>
<id>local</id>
<name>Local repository in project tree</name>
<url>file:${basedir}/lib</url>
</repository>
Afterwards Maven will try to find a repository in the "lib" folder in your project. Let's assume you want this dependency in the local repository (hopefully something with better chosen IDs, but I decided to keep an existing pattern here):
<dependency>
<groupId>owlapi</groupId>
<artifactId>owlapi</artifactId>
<version>2.2.0</version>
</dependency>
What you need for this is a folder structure representing those three bits of information: groupId, artifactId and version (in that order), i.e.
lib/owlapi/owlapi/2.2.0. In that folder Maven expects at least four things: the JAR file, a matching POM file and the SHA1 sums for both. All files are named using the artifactId and the version, i.e. "owlapi-2.2.0.jar" for the JAR, the same for the POM but with the different extension.To get the SHA1 sums you can do this (assuming you run bash and have the sha1sum tool available):
for file in `ls`; do sha1sum $file > $file.sha1; done
If you are nice and add the sources (has to be a JAR with "-sources" in the name), then the result looks something like this:

The POM itself just contains the basic description (and possible dependencies):
<project>
<modelVersion>4.0.0</modelVersion>
<groupId>owlapi</groupId>
<artifactId>owlapi</artifactId>
<packaging>jar</packaging>
<name>OWLAPI</name>
<version>2.2.0</version>
<url>http://owlapi.sourceforge.net/</url>
<description>Java interface and implementation for the Web Ontology Language OWL</description>
<licenses>
<license>
<name>GNU Lesser General Public License, Version 3</name>
<url>http://www.gnu.org/licenses/lgpl-3.0.txt</url>
<distribution>repo</distribution>
</license>
</licenses>
<scm>
<url>http://sourceforge.net/svn/?group_id=90989</url>
</scm>
<dependencies>
</dependencies>
</project>
That's all there is -- next time you run Maven it should "download" the files from that location. Considering that the POM also provides a uniform way of storing licence, source and version information it is actually a quite useful approach for storing dependencies inside your project's space.
Wednesday, February 25, 2009
Using Firefox profiles
Firefox can get awfully slow once you have all your favorite web-developer tools installed. As much as I love Firebug and the Web Developer extension, they certainly do not enhance your browsing experience.
The solution to that problem is to run multiple instances of Firefox with different profiles. If you run Firefox like this:
then you get a dialog to configure profiles. You can start a preconfigured profile with:
Every profile has its own settings, most importantly it has its own configuration for extensions. By creating a profile with only the basic Firefox extensions and one with all the web-developer tools you can have a fast browser and one that does all its magic for development purposes.
Note that the "-no-remote" is not always necessary. It stops Firefox from reusing an already running instance, so you really need it only if there is a Firefox open that uses a profile you don't want. Having "-no-remote" will cause errors if there is an instance running that uses the same profile -- it's quite a straightforward error message, though.
The solution to that problem is to run multiple instances of Firefox with different profiles. If you run Firefox like this:
firefox -Profilemanager -no-remote
then you get a dialog to configure profiles. You can start a preconfigured profile with:
firefox -p $PROFILE_NAME -no-remote
Every profile has its own settings, most importantly it has its own configuration for extensions. By creating a profile with only the basic Firefox extensions and one with all the web-developer tools you can have a fast browser and one that does all its magic for development purposes.
Note that the "-no-remote" is not always necessary. It stops Firefox from reusing an already running instance, so you really need it only if there is a Firefox open that uses a profile you don't want. Having "-no-remote" will cause errors if there is an instance running that uses the same profile -- it's quite a straightforward error message, though.
Using fake query parameters to identify resource versions
When setting the cache expiry headers to somewhere in the far future as to make browsers not hit your server again for a long time (practically forever), you need some way to get the browser to newer versions of your otherwise static files. So far I have used a pattern containing the version of the artifact as part of the path:
http://my.server/js/lib/v123/lib.js
I just noticed the Sonatype repository using a different scheme, which is more like this:
http://my.server/js/lib/lib.js?v123
The version number is stored in a query parameter in this scheme. I assume that this parameter is actually ignored as most webservers would do with static content.
The advantages I see in this approach are:
http://my.server/js/lib/v123/lib.js
I just noticed the Sonatype repository using a different scheme, which is more like this:
http://my.server/js/lib/lib.js?v123
The version number is stored in a query parameter in this scheme. I assume that this parameter is actually ignored as most webservers would do with static content.
The advantages I see in this approach are:
- updates can be done in-place (easier deployment, no need to keep multiple copies around)
- the target doesn't even have to be aware of the scheme
- the client could even go as far as generating a URL based on its revision, causing a retrieval for each of its upgrades, which would be too much but very safe
- any reference will always retrieve the newest version (which could break things subtly if for some reason old references are still around somewhere)
- (related to the one above) it's just not a proper URI since it identifies a resource with the query parameter (unless you consider the resource as spanning all versions and the versions different representations of it)
- I don't know if I trust all caches to handle the query part properly (I never even looked into that)
Sunday, February 22, 2009
Extracting Subversion status from Maven or Ant build
UPDATE 2009/02/24: the original version didn't work, it worked on my machine only since the task quietly falls back to the command line interface if loading SVNkit fails. Since it needs not only SVNkit, but also the JavaHL API for SVNkit (I can't find that documented anywhere, but the source tells you), it failed in the original version. There was also an issue with the version of SVNkit since I took what was available in the Maven repositories (1.1.0), but that version is too old to handle SVN 1.5 working copies. The fix was to replace a dependency on SVNkit 1.1.0 with one on SVNkit-JavaHL 1.2.2 (which in turn depends on SVNkit 1.2.2).
To extract the current revision and potential changes of a Subversion working copy during a build a combination of the SVN Ant task and SVNKit can be used, which means it is a 100% pure Java solution. It requires around 2MB of libraries in the build chain, which will not be deployed.
Here is the solution in the context of Maven, bound to the "process-resource" phase of the lifecycle. Note that I declare a dependency on the Ant task (and transitively to the SVN client adapter) that is resolved against a local repository. I couldn't find those in a standard repository. The SVNkit available, is not the youngest, so we have a newer one in a local repository, too -- including the svnkit-javahl.jar, which contains the compatibility API the Ant task uses. You should be able to get away with four JARs: one for the Ant task itself, one for the client adapter and the SVNkit library as well as its JavaHL adapter.
If you want to use the solution in Ant, just use the part in the
You don't have to use SVNkit (makes most of the solution's size) but can use JavaHL or the command line interface instead by changing the attributes of the
To extract the current revision and potential changes of a Subversion working copy during a build a combination of the SVN Ant task and SVNKit can be used, which means it is a 100% pure Java solution. It requires around 2MB of libraries in the build chain, which will not be deployed.
Here is the solution in the context of Maven, bound to the "process-resource" phase of the lifecycle. Note that I declare a dependency on the Ant task (and transitively to the SVN client adapter) that is resolved against a local repository. I couldn't find those in a standard repository. The SVNkit available, is not the youngest, so we have a newer one in a local repository, too -- including the svnkit-javahl.jar, which contains the compatibility API the Ant task uses. You should be able to get away with four JARs: one for the Ant task itself, one for the client adapter and the SVNkit library as well as its JavaHL adapter.
If you want to use the solution in Ant, just use the part in the
<tasks> element and replace the classpathref with a suitable classpath containing the three JARs mentioned above.You don't have to use SVNkit (makes most of the solution's size) but can use JavaHL or the command line interface instead by changing the attributes of the
<svn> task. I much prefer the pure Java way, though.
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-antrun-plugin</artifactId>
<executions>
<execution>
<id>svn_status</id>
<phase>process-resources</phase>
<configuration>
<tasks>
<taskdef name="svn"
classname="org.tigris.subversion.svnant.SvnTask"
classpathref="maven.plugin.classpath" />
<svn javahl="false" svnkit="true">
<!-- change @path if not interested in the base directory -->
<!-- set @processUnversioned to "true" if new files should show up as modifications -->
<wcVersion path="${basedir}" prefix="buildInfo.svn." processUnversioned="false"/>
</svn>
<!-- set properties not set by wcVersion to "false" so we get nice output -->
<property name="buildInfo.svn.modified" value="false"/>
<property name="buildInfo.svn.mixed" value="false"/>
<!-- set @file to wherever you want the properties file -->
<!-- we copy all information from wcVersion, even if it is redundant -->
<propertyfile file="target/classes/META-INF/build.properties" comment="Build information">
<entry key="svn.repository.url" value="${buildInfo.svn.repository.url}"/>
<entry key="svn.repository.path" value="${buildInfo.svn.repository.path}"/>
<entry key="svn.revision.max" value="${buildInfo.svn.revision.max}"/>
<entry key="svn.revision.max-with-flags" value="${buildInfo.svn.revision.max-with-flags}"/>
<entry key="svn.revision.range" value="${buildInfo.svn.revision.range}"/>
<entry key="svn.committed.max" value="${buildInfo.svn.committed.max}"/>
<entry key="svn.committed.max-with-flags" value="${buildInfo.svn.committed.max-with-flags}"/>
<entry key="svn.modified" value="${buildInfo.svn.modified}"/>
<entry key="svn.mixed" value="${buildInfo.svn.mixed}"/>
<entry key="build.timestamp"
type="date"
pattern="yyyy-MM-dd'T'HH:mm:ss"
value="now"/>
<!-- put more useful information here -->
</propertyfile>
</tasks>
</configuration>
<goals>
<goal>run</goal>
</goals>
</execution>
</executions>
<dependencies>
<dependency>
<groupId>ant</groupId>
<artifactId>ant-nodeps</artifactId>
<version>1.6.5</version>
</dependency>
<dependency>
<groupId>ant</groupId>
<artifactId>ant-optional</artifactId>
<version>1.5.3-1</version>
</dependency>
<dependency>
<groupId>org.tigris.subversion</groupId>
<artifactId>svnant</artifactId>
<version>1.2.1</version>
</dependency>
<dependency>
<groupId>com.svnkit</groupId>
<artifactId>svnkit-javahl</artifactId>
<version>1.2.2</version>
</dependency>
</dependencies>
</plugin>
Tuesday, February 17, 2009
Moving from Mercurial to Subversion
Somehow all the world seems to move Subversion repositories into Mercurial but not the other way around.
In many ways I understand that, but I had to move my own little project stored in a local Mercurial repository onto the official infrastructure, which happens to use Subversion. That cost me first some time searching for a migration solution and then hacking one myself.
Interestingly the main issues I had in writing my migration script where mostly Subversion related. While hg sometimes required parsing some output to get to particular information (scary if I should ever need to reuse this script again), svn threw a few more problems at me:
The one weird thing Mercurial does is to somehow move existing .svn folders around into new directories (I believe that happens only if the directory is a result of a move). Once that happened the SVN working copy is entirely broken until those folders are removed.
After running it against the central repository I also figured that I probably should have passed the original commit timestamp along in the commit message. I'd certainly add that if I would ever do it again since it is easily extracted from the "hg log" command. Similarly the original committer could be passed along, which in my case just didn't matter since it matched anyway.
Here is the resulting script, which worked for me. Since it is hacked together it is probably not reusable straight away, but could be useful as inspiration or basis of the next hack. Read the comments.
Somehow it seems I'll have to avoid Mercurial a bit longer until I'm in an environment where I know it is supported. It's not such a surprising result, but a real pity since I quite like it so far.
In many ways I understand that, but I had to move my own little project stored in a local Mercurial repository onto the official infrastructure, which happens to use Subversion. That cost me first some time searching for a migration solution and then hacking one myself.
Interestingly the main issues I had in writing my migration script where mostly Subversion related. While hg sometimes required parsing some output to get to particular information (scary if I should ever need to reuse this script again), svn threw a few more problems at me:
- svn returns zero unless something really went wrong. Even doing "svn status" on a non-SVN location is perfectly ok according to the return code
- it is really easy to create a working copy that confuses svn, up to the point where any standard command fails due to supposed locking issues, while a "svn cleanup" as proposed by the other commands just whinges about something not being a working copy without actually fixing anything
- generally error reporting seems arbitrary at times
- some commands have weird behavior, most noticeably "svn add" recurses into new folders, but not existing ones. Somehow I expected recursion to be unconditional or at least have an option to do so
The one weird thing Mercurial does is to somehow move existing .svn folders around into new directories (I believe that happens only if the directory is a result of a move). Once that happened the SVN working copy is entirely broken until those folders are removed.
After running it against the central repository I also figured that I probably should have passed the original commit timestamp along in the commit message. I'd certainly add that if I would ever do it again since it is easily extracted from the "hg log" command. Similarly the original committer could be passed along, which in my case just didn't matter since it matched anyway.
Here is the resulting script, which worked for me. Since it is hacked together it is probably not reusable straight away, but could be useful as inspiration or basis of the next hack. Read the comments.
#!/bin/bash
# DANGER: written as a once-off script, not suitable for naive consumption. Use at
# your own peril. It has been tested on one case only.
#
# Potential issues for reuse:
# * no sanity checks anywhere (don't call it with the wrong parameters)
# * no handling of branches
# * certain layout of the results of hg commands is assumed
# * all commits come from the user running the script
# * move operations probably won't appear in the history as such
# * we assume the SVN side doesn't change
#
# Also note: .hgignore will be checked in and probably contains some entries
# that should be added to svn:ignore after the operation
HG_SOURCE=$1 # the source is a normal hg repository
SVN_TARGET=$2 # the target is a folder within a SVN working copy (e.g. /trunk)
export QUIET_FLAG=-q # -q for quiet, empty for verbose
echo Converting Mercurial repository at $HG_SOURCE into Subversion working copy at $SVN_TARGET
pushd $SVN_TARGET
hg init .
pushd $HG_SOURCE
TIP_REV=`hg tip | head -1 | sed -e "s/[^ ]* *\([^:]*\)/\1/g"`
popd # out of $HG_SOURCE
for i in `seq $TIP_REV`
do
echo "Fetching Mercurial revision $i/$TIP_REV"
hg $QUIET_FLAG pull -u -r $i $HG_SOURCE
# in the next line use sed since 'tail --lines=-5' leaves too much for one-line messages
HG_LOG_MESSAGE=`hg -R $HG_SOURCE -v log -r $i | sed -n "6,$ p" | head --lines=-2`
echo "- removing deleted files"
for fileToRemove in `svn status | grep '^!' | sed -e 's/^! *\(.*\)/\1/g'`
do
svn remove $QUIET_FLAG $fileToRemove
done
echo "- removing empty directories" # needed since Mercurial doesn't manage directories
for dirToRemove in `svn status | grep '^\~' | sed -e 's/^\~ *\(.*\)/\1/g'`
do
if [ "X`ls -am $dirToRemove`" = "X., .., .svn" ]
then
rm -rf $dirToRemove # remove first, otherwise working copy is broken for some reason only SVN knows
svn remove $QUIET_FLAG $dirToRemove
fi
done
echo "- adding files to SVN control"
# 'svn add' recurses only into new folders, so we need to recurse ourselves
for fileToAdd in `svn status | grep '^\?' | grep -v "^\? *\.hg$" | sed -e 's/^\? *\(.*\)/\1/g'`
do
if [ -d $fileToAdd ]
then
# Mercurial seems to copy existing directories on moves or something like that -- we
# definitely get some .svn subdirectories in newly created directories if the original
# action was a move. New directories should never contain a .svn folder since that breaks
# SVN
for accidentalSvnFolder in `find $fileToAdd -type d -name ".svn"`
do
rm -rf $accidentalSvnFolder
done
fi
svn add $QUIET_FLAG $fileToAdd
done
echo "- committing"
svn ci $QUIET_FLAG -m "$HG_LOG_MESSAGE"
echo "- done"
done
popd # out of $SVN_TARGET
Somehow it seems I'll have to avoid Mercurial a bit longer until I'm in an environment where I know it is supported. It's not such a surprising result, but a real pity since I quite like it so far.
Thursday, February 12, 2009
Process start and stop, the easy way
Here is a pair of scripts that can be used to start and stop a Java process (or something else) on a Linux/UNIX box using bash:
"start.sh":
"stop.sh":
Use with caution, these are not production-ready ;-)
"start.sh":
nohup /usr/lib/jvm/java-1.6.0-sun/bin/java -jar Pronto-0.1-SNAPSHOT.jar 1> stdout.txt 2> stderr.txt &
echo $! > Pronto.pid
"stop.sh":
kill `cat Pronto.pid`
rm Pronto.pid
Use with caution, these are not production-ready ;-)
Monday, February 9, 2009
Defending against XSS attacks in Freemarker
While Freemarker is quite rich in features, it seems to lack support for programmatically declaring HTML-escaping the default behavior for property access. You need to either add a
This really has to be done on every file, including those being included such as macro definitions.
Both approaches rely on people remembering to do the right thing, and I don't trust anyone that much, particularly not myself. So instead I decided to add this bit of wrapper code programmatically in the code that loads the template. I took the idea from a posting on the freemarker-user mailing list. Instead of using the normal ClassTemplateLoader, I now do this:
This uses the following class:
Note that this means that in some cases you might need to escape the escaping, which Freemarker allows with the
?html to every access or wrap every single template into this:
<#escape x as x?html>
... your template code ...
</#escape>
This really has to be done on every file, including those being included such as macro definitions.
Both approaches rely on people remembering to do the right thing, and I don't trust anyone that much, particularly not myself. So instead I decided to add this bit of wrapper code programmatically in the code that loads the template. I took the idea from a posting on the freemarker-user mailing list. Instead of using the normal ClassTemplateLoader, I now do this:
final TemplateLoader templateLoader = new ClassTemplateLoader(this.getClass(), templatePath){
@Override
public Reader getReader(Object templateSource, String encoding) throws IOException {
return new WrappingReader(super.getReader(templateSource, encoding), "<#escape x as x?html>", "");
}
};
configuration.setTemplateLoader(templateLoader);
This uses the following class:
package domain.your.util;
import java.io.IOException;
import java.io.Reader;
import java.util.logging.Level;
import java.util.logging.Logger;
public class WrappingReader extends Reader {
private final Reader originalReader;
private final char[] prologue;
private final char[] epilogue;
private int pos = 0;
private int firstEpilogueChar = -1;
private boolean closed = false;
public WrappingReader(Reader originalReader, char[] prologue, char[] epilogue, Object lock) {
super(lock);
this.originalReader = originalReader;
this.prologue = prologue;
this.epilogue = epilogue;
}
public WrappingReader(Reader originalReader, char[] prologue, char[] epilogue) {
this.originalReader = originalReader;
this.prologue = prologue;
this.epilogue = epilogue;
}
public WrappingReader(Reader originalReader, String prologue, String epilogue, Object lock) {
super(lock);
this.originalReader = originalReader;
this.prologue = prologue.toCharArray();
this.epilogue = epilogue.toCharArray();
}
public WrappingReader(Reader originalReader, String prologue, String epilogue) {
this.originalReader = originalReader;
this.prologue = prologue.toCharArray();
this.epilogue = epilogue.toCharArray();
}
@Override
public int read(char[] cbuf, int off, int len) throws IOException {
if (closed) {
throw new IOException("Reader has been closed already");
}
int oldPos = pos;
Logger.getLogger(getClass().getName()).log(Level.FINE, String.format("Reading %d characters from position %d", len, pos));
if (pos < this.prologue.length) {
final int toCopy = Math.min(this.prologue.length - pos, len);
Logger.getLogger(getClass().getName()).log(Level.FINE, String.format("Copying %d characters from prologue", toCopy));
System.arraycopy(this.prologue, pos, cbuf, off, toCopy);
pos += toCopy;
if (toCopy == len) {
Logger.getLogger(getClass().getName()).log(Level.FINE, "Copied from prologue only");
return len;
}
}
if (firstEpilogueChar == -1) {
final int copiedSoFar = pos - oldPos;
final int read = originalReader.read(cbuf, off + copiedSoFar, len - copiedSoFar);
Logger.getLogger(getClass().getName()).log(Level.FINE, String.format("Got %d characters from delegate", read));
if (read != -1) {
pos += read;
if (pos - oldPos == len) {
Logger.getLogger(getClass().getName()).log(Level.FINE, "We do not reach epilogue");
return len;
}
}
firstEpilogueChar = pos;
}
final int copiedSoFar = pos - oldPos;
final int epiloguePos = pos - firstEpilogueChar;
final int toCopy = Math.min(this.epilogue.length - epiloguePos, len - copiedSoFar);
if((toCopy <= 0) && (copiedSoFar == 0)) {
return -1;
}
Logger.getLogger(getClass().getName()).log(Level.FINE, String.format("Copying %d characters from epilogue", toCopy));
System.arraycopy(this.epilogue, epiloguePos, cbuf, off + copiedSoFar, toCopy);
pos += toCopy;
Logger.getLogger(getClass().getName()).log(Level.FINE, String.format("Copied %d characters, now at position %d", pos-oldPos, pos));
return pos - oldPos;
}
@Override
public void close() throws IOException {
originalReader.close();
closed = true;
}
}
Note that this means that in some cases you might need to escape the escaping, which Freemarker allows with the
<#noescape> directive. You also can't use template configuration via the <#ftl> directive anymore, since that would need to be before the <#escape>. Since I never felt the urge to use it, I don't care.
Sunday, February 8, 2009
Sample code for Dojo/Dijit
When looking for variations of Dijit widgets this is a useful resource: Dojo's testcases for form controls. It contains files with test cases for variants of the different form items, usually providing much more information about the widgets than any of the documentation. The danger is that this is testing the nightly build, so some features might not be available in your version of Dojo.
Creating closures in JavaScript loops
JavaScript has closures, but only one per loop. If you e.g. try this:
then there will be only one closure for the whole loop, which means all menu items have the same callback using the last values in the categories array.
The workaround is to create the closure in another function, in which case the closure is created in the context of a different stack trace each time.
for (i in categories) {
category = categories[i];
var menuItem = new dijit.MenuItem({
label: category.name,
onClick: function(){
dojo.query("#currentCategoryId").attr('value', category.id);
categoryButton.attr('label', category.name);
};
});
}
then there will be only one closure for the whole loop, which means all menu items have the same callback using the last values in the categories array.
The workaround is to create the closure in another function, in which case the closure is created in the context of a different stack trace each time.
for (i in categories) {
category = categories[i];
var menuItem = new dijit.MenuItem({
label: category.name,
onClick: createCallback(category.name, category.id, categoryButton)
});
}
/* .... */
function createCallback(name, id, categoryButton) {
return function(){
dojo.query("#currentCategoryId").attr('value', id);
categoryButton.attr('label', name);
};
}
Subscribe to:
Posts (Atom)
